Easiest Way to Build a RAG AI Agent Application


7 min read

Table of contents
We’ve all experienced LLMs hallucinating spot-on with some answers and completely off with others.
That’s where RAG steps in as the built-in search engine your LLMs need overcoming their limitations.
In this guide, we’ll build a RAG powered AI agent application. This walkthrough guide will cover the following:
RAG introduction
Prerequisites to get started with the app
Building a Document QnA RAG app
Setting up a Next.js app
Deploying the project
What is RAG?
RAG (Retrieval-Augmented Generation) takes LLMs to the next level by connecting them to real-time data sources before generating a response. Your AI stops guessing and starts referencing up-to-date, accurate info from your specific datasets.
Why does RAG matter?
While LLMs are advanced, they can still hallucinate or give outdated info. RAG fixes this by grounding responses in reliable, real-time data. It ensures trust and accuracy, especially when dealing with specialized content.
How does RAG work?
Create External Data: Connect your LLM to sources like APIs or databases.
Retrieve Information: Fetch relevant data for each query.
Augment the Prompt: Combine user queries with fetched data for accuracy.
Update Data: Keep sources refreshed for ongoing precision.
The diagrammatic representation of how the RAG works:
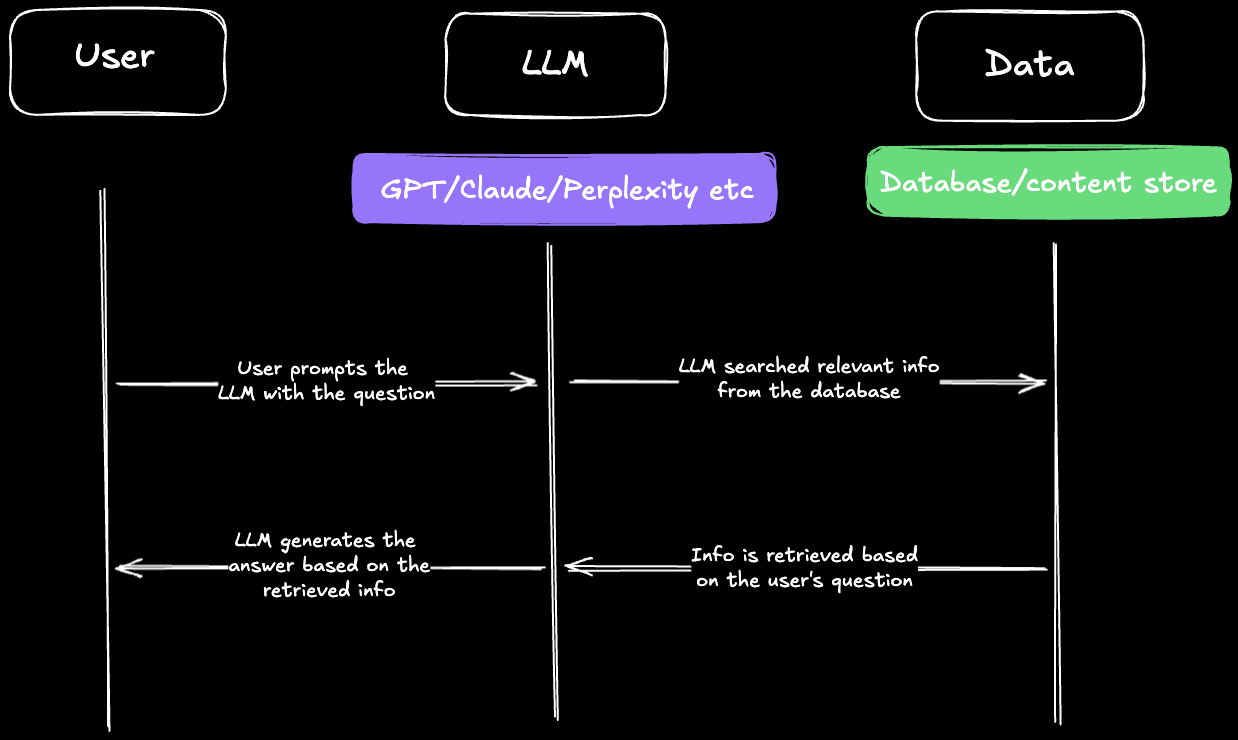
Now that you know about RAG, let’s walk through how to build a Document QnA RAG AI agent app:
Prerequisites
Before getting started, make sure you have the following ready:
Langbase Account: Sign up on ⌘ Langbase and get access to the dashboard.
Next.js Knowledge: Basic understanding of Next.js for building a web application.
Node.js: Installed on your local machine.
Tailwind CSS Knowledge: Understanding of Tailwind CSS to design the application.
Deployment Platform: Have an account with Vercel, Netlify, or Cloudflare for deployment.
We'll start by setting up a Langbase memory (Memory + AI Agent Pipe = RAG at Langbase), uploading data, and connecting it to a pipe. Then, we’ll build a Next.js app using Langbase SDK to leverage that pipe for real-time responses.
Ready? Let’s go!
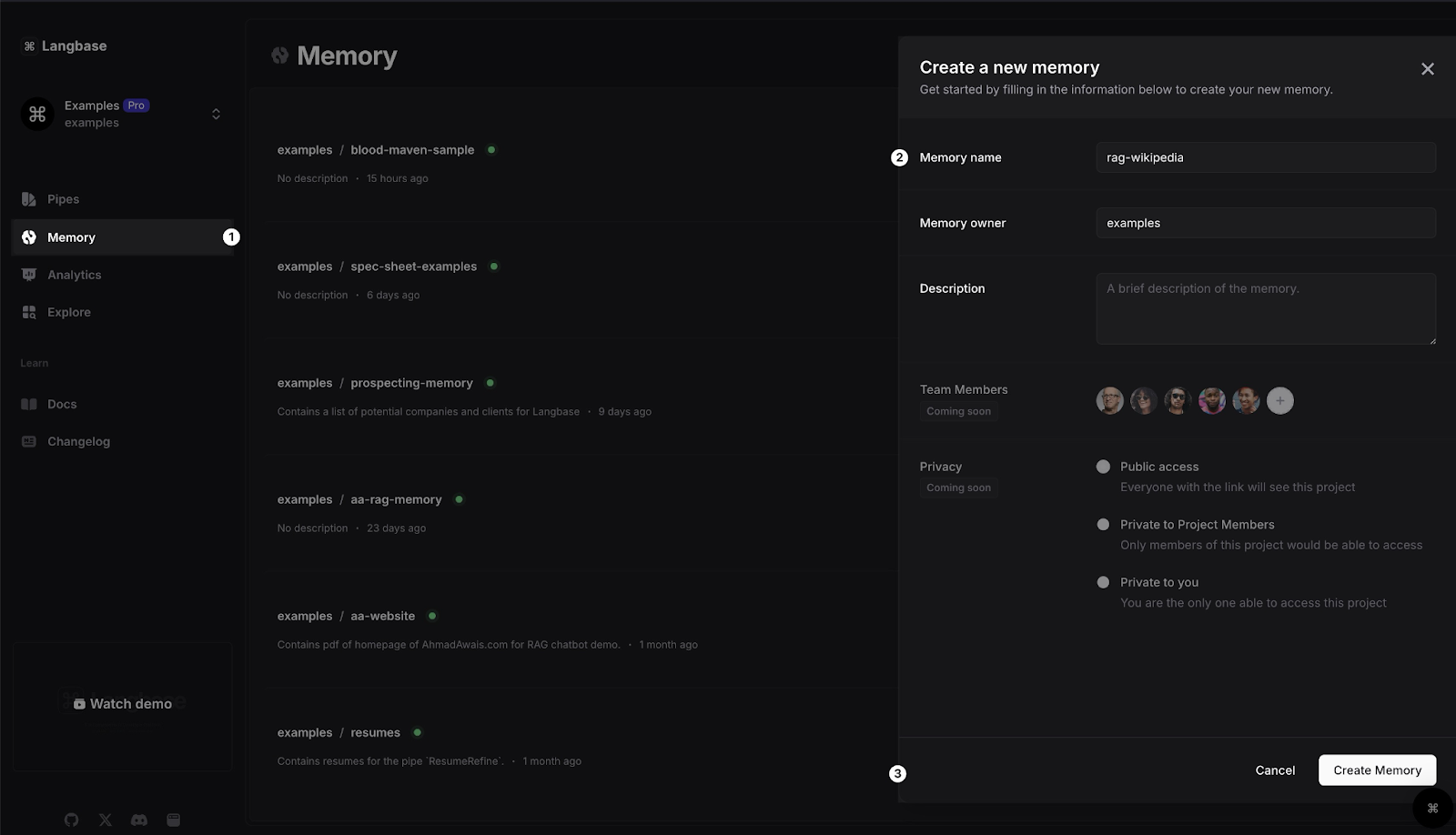
1- Create a Memory
Memory is a managed API that acts as a private search engine for developers. It combines vector storage, RAG, and internet access to help build powerful AI features.
In the Langbase dashboard, navigate to the Memory section, create a new memory and name it rag-wikipedia. You can also add a description to the memory.
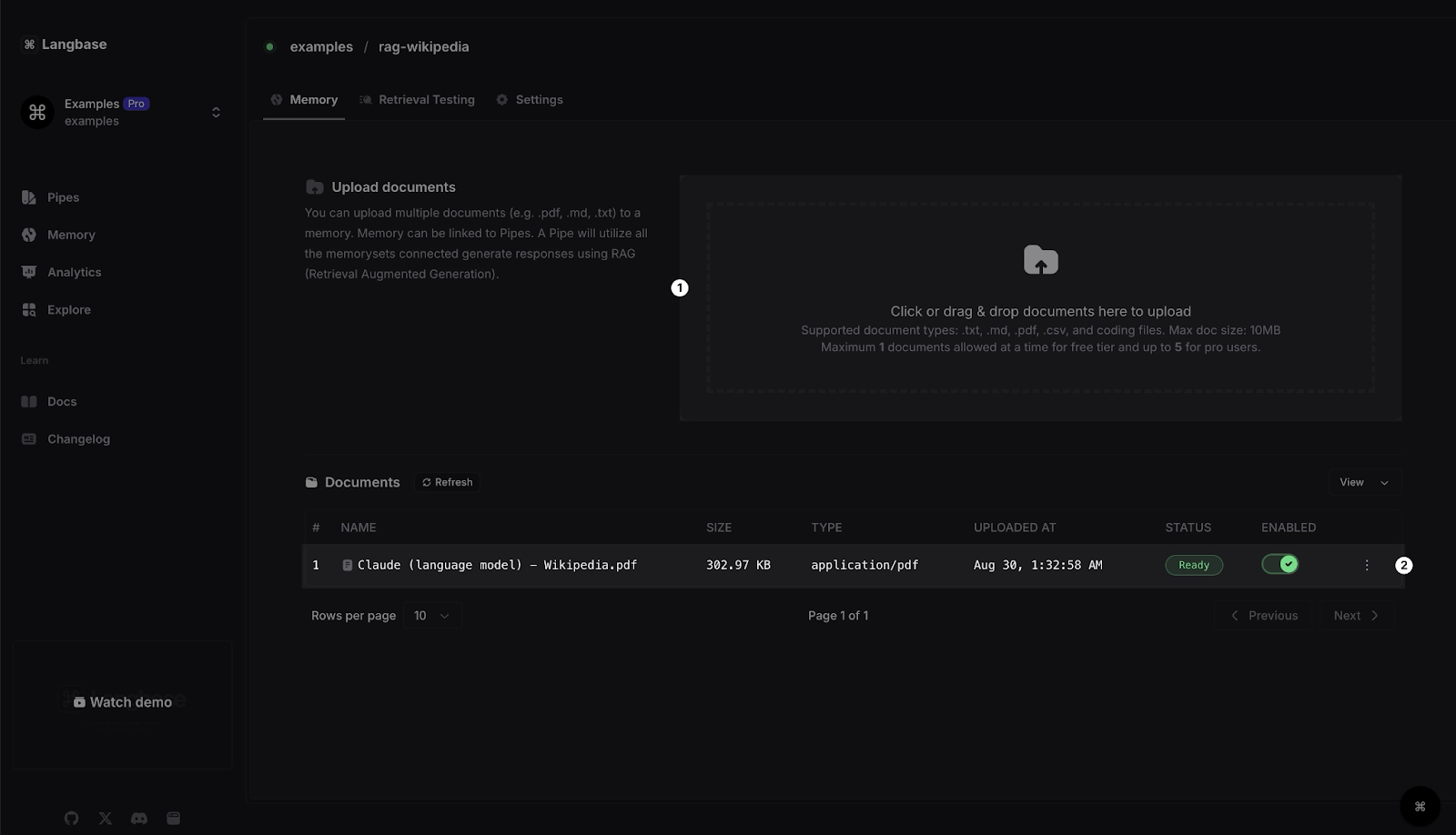
2- Upload RAG Data
Upload the data to the memory you created. You can upload any data for your RAG. For this example, we uploaded a PDF file of the Wikipedia page of Claude.
You can either drag and drop the file or click on the upload button to select the file. Once uploaded, wait a few minutes to let Langbase process the data. Langbase takes care of chunking, embedding, and indexing the data for you.
Click on the Refresh button to see the latest status. Once you see the status as Ready, you can move to the next step.
The next step is to create an AI agent pipe that will be responsible for all the backend work behind the application.
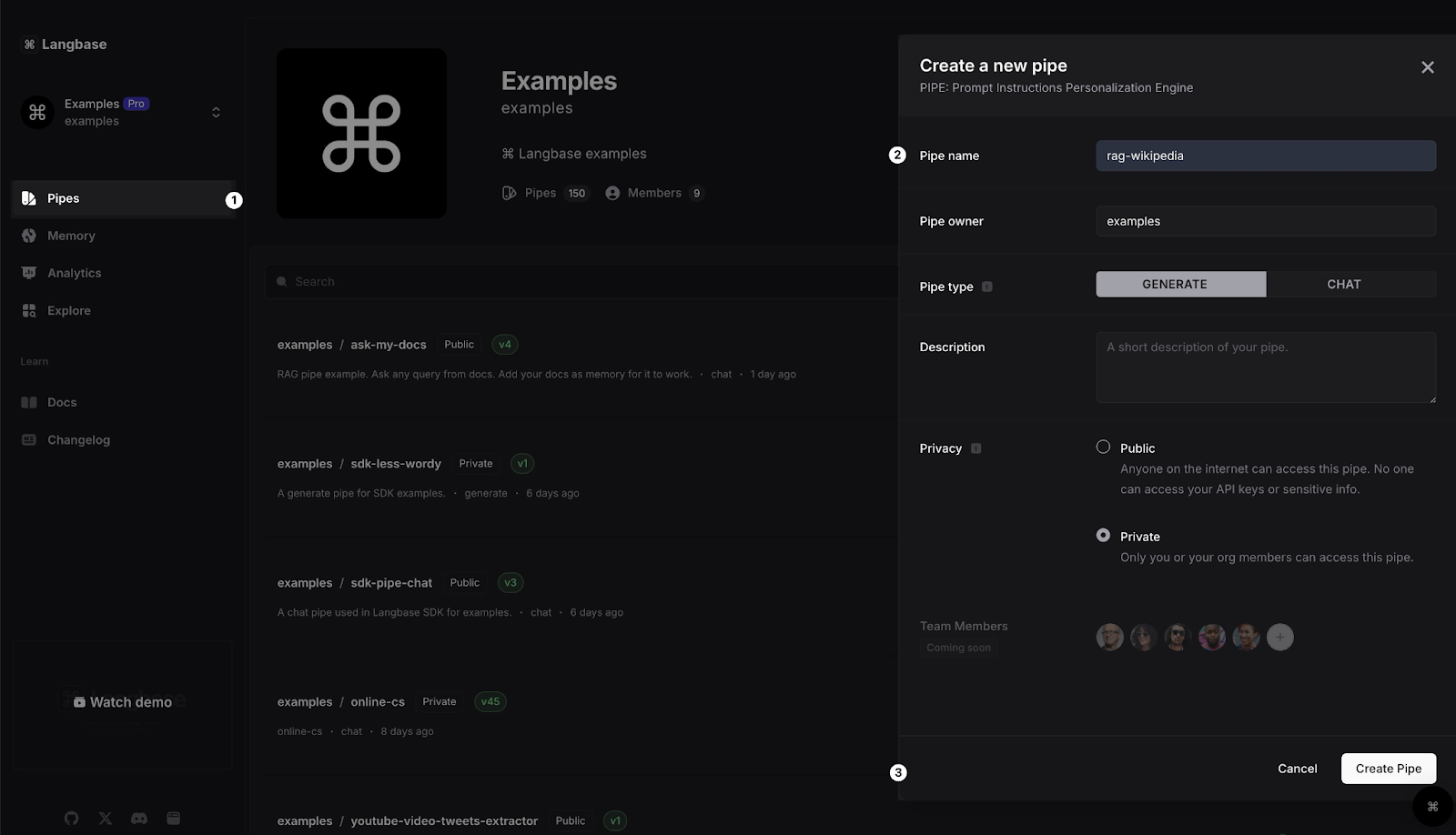
3- Create an AI Agent Pipe
In your Langbase dashboard, create a new pipe and name it rag-wikipedia. You can also add a description to the pipe. Alternatively you can always type pipe.new in your search bar to create a new pipe.
4- Connect Memory to AI Agent Pipe
Open the newly created pipe and click on the Memory button. From the dropdown, select the memory you created in the previous step and that's it.
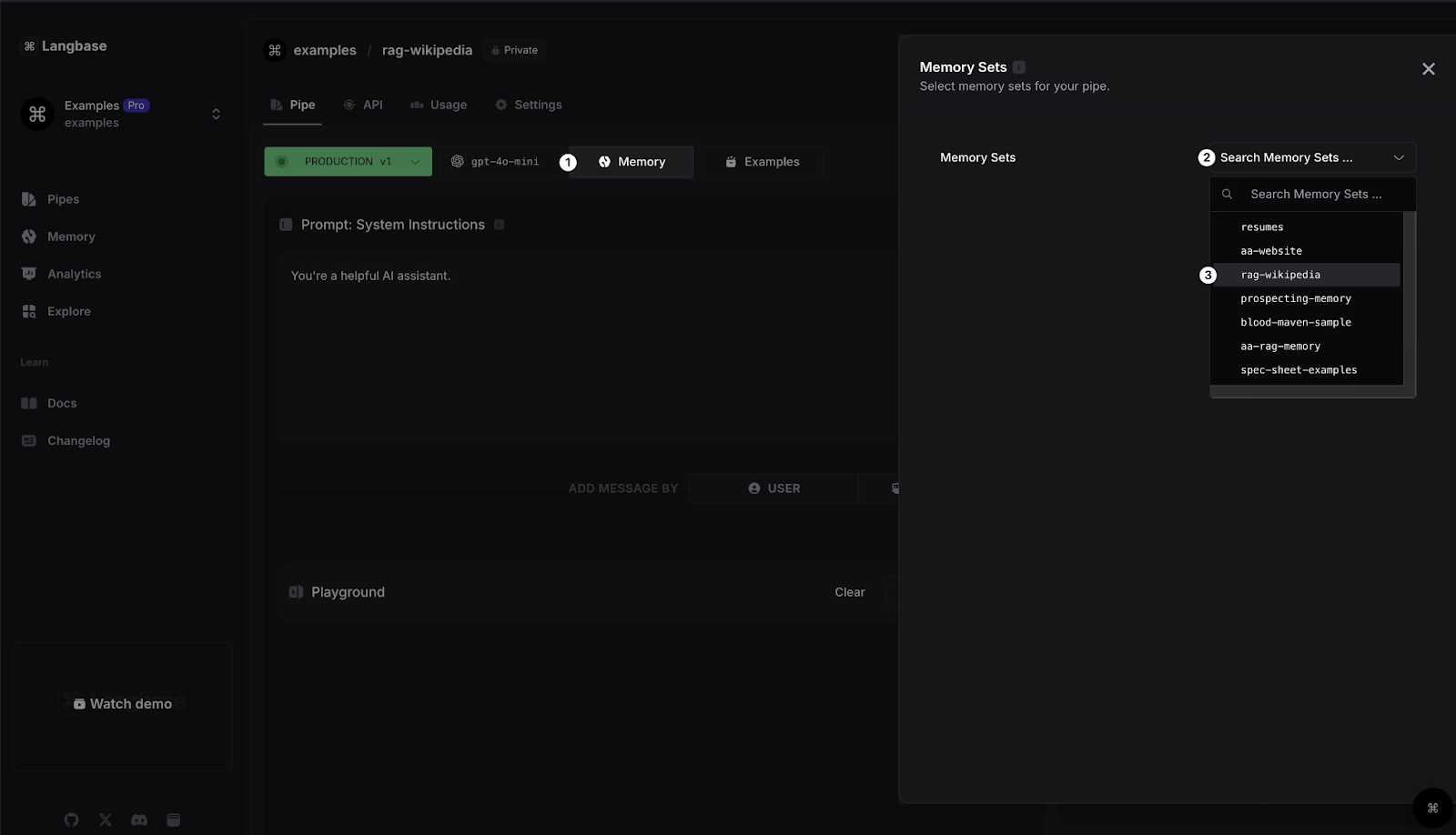
Now that we have created a memory, uploaded data to it, and connected it to an AI agent pipe, we can create a Next.js application that uses Langbase SDK to generate responses.
5- Clone the Starter Project
Clone the RAG Starter Project to get started. The app contains a single page with a form to ask a question from documents. This project uses:
6- Install Dependencies and Langbase SDK
Install the dependencies using the following command:
npm install
Install the Langbase SDK using the following command:
npm install langbase
7- Create a Route
Create a route app/api/generate/route.ts and add the following code:
import { Pipe } from 'langbase';
import { NextRequest } from 'next/server';
/**
* Generate response and stream from Langbase Pipe.
*
* @param req
* @returns
*/
export async function POST(req: NextRequest) {
try {
if (!process.env.LANGBASE_PIPE_API_KEY) {
throw new Error(
'Please set LANGBASE_PIPE_API_KEY in your environment variables.'
);
}
const { prompt } = await req.json();
// 1. Initiate the Pipe.
const pipe = new Pipe({
apiKey: process.env.LANGBASE_PIPE_API_KEY
});
// 2. Generate a stream by asking a question
const stream = await pipe.streamText({
messages: [{ role: 'user', content: prompt }]
});
// 3. Done, return the stream in a readable stream format.
return new Response(stream.toReadableStream());
} catch (error: any) {
return new Response(error.message, { status: 500 });
}
}
This code handles a POST request in a Next.js app to generate a response from a Langbase Pipe.
It checks if the
LANGBASE_PIPE_API_KEYis set.Retrieves the user's question (the prompt) from the request.
Initializes a Langbase Pipe using the API key.
Sends the user's question to the Pipe, generating a real-time response.
Streams the response back to the user in a readable format.
If there's an error, it returns the error message with a 500 status.
8- More Code!
Go to starters/rag-ask-docs/components/langbase/docs-qna.tsx and add following import:
import { fromReadableStream } from 'langbase';
Add the following code in DocsQnA component after the states declaration:
const handleSubmit = async (e: React.FormEvent) => {
// Prevent form submission
e.preventDefault();
// Prevent empty prompt or loading state
if (!prompt.trim() || loading) return;
// Change loading state
setLoading(true);
setCompletion('');
setError('');
try {
// Fetch response from the server
const response = await fetch('/api/generate', {
method: 'POST',
body: JSON.stringify({ prompt }),
headers: { 'Content-Type': 'text/plain' },
});
// If response is not successful, throw an error
if (response.status !== 200) {
const errorData = await response.text();
throw new Error(errorData);
}
// Parse response stream
if (response.body) {
// Stream the response body
const stream = fromReadableStream(response.body);
// Iterate over the stream
for await (const chunk of stream) {
const content = chunk?.choices[0]?.delta?.content;
content && setCompletion(prev => prev + content);
}
}
} catch (error: any) {
setError(error.message);
} finally {
setLoading(false);
}
};
The above code defines the handleSubmit function that handles form submissions in a React component by preventing the default submission behavior and validating the input prompt. If the prompt is valid, it sets a loading state and clears any previous responses or errors. It then sends a POST request to the /api/generate endpoint with the prompt. If the server response is not successful, it throws an error.
For successful responses, it streams the content and appends it to the completion state. Finally, it catches any errors that occur and resets the loading state once the process is complete.
Next, replace the following piece of code in DocsQnA component:
onSubmit={(e) => {
e.preventDefault();
}}
With the following code:
onSubmit={handleSubmit}
9- Add API Key of the AI Agent Pipe
Create a copy of .env.local.example and rename it to .env.local. Add the API key of the pipe that we created in step 3 to the .env.local file:
# !! SERVER SIDE ONLY !!
# Pipes.
LANGBASE_PIPE_API_KEY="YOUR_PIPE_API_KEY"
10- Run and Deploy the Project
Run the project using the following command:
npm run dev
Your app should be running on http://localhost:3000. You can now ask questions from the documents you uploaded to the memory.
🎉 That's it! You have successfully implemented a RAG application. It is a Next.js application you can deploy to any platform of your choice like Vercel, Netlify, or Cloudflare.
Live Demo
You can see the live demo of this project here.
Further resources:
Complete code on GitHub.
Complete guide here.
AI agent pipe used in this example on Langbase Pipes.